Introduction to Scheduling¶
As explained elsewhere in more detail, an HPC cluster consists of multiple computers connected via a network and working together. Multiple users can use the system simultaneously to do their work. This means that the system needs to join multiple computers (nodes) to provide a coherent view of them and the same time partition the system to allow multiple users to work concurrently.
user 1 user 2 ...
.---. .---. .---. .---.
| J | | J | | J | | J |
| o | | o | | o | | o | ...
| b | | b | | b | | b |
| 1 | | 2 | | 3 | | 4 |
'---' '---' '---' '---'
.------------------------------------------.
| Cluster Scheduler |
'------------------------------------------'
.----------. .------------. .------------.
| multiple | | separate | | computers |
'----------' '------------' '------------'
Interlude: Partitioning Single Computers¶
Overall, this partitioning is not so different from how your workstation or laptop works. Most likely, your computer (or even your smartphone) has multiple processors (or cores). You can run multiple programs on the same computer and the fact that (a) there is more than one core and (b) there is more than one program running is not known to the running programs (unless they explicitly communicate with each other). Different programs can explicitly take advantage of the multiple processor cores. The main difference is that you normally use your computer in an interactive fashion (you perform an action and expect an immediate reaction).
Even with a single processor (and core), your computer manages to run more than one program at the same time. This is done with the so-called time-slicing approach where the operating system lets each programs run in turn for a short time (a few milliseconds). A program with a higher priority will get more time slices than one with a lower (e.g., your audio player has real-time requirements and you will hear artifacts if it is starved for compute resources). Your operating system protects programs from each other by creating an address space for each. When two programs are running, the value of the memory at any given position in one program is independent from the value in the other program. Your operating system offers explicit functionality for sharing certain memory areas that two programs can use to exchange data efficiently.
Similarly, file permissions with Unix users/groups or Unix/Windows ACLs (access control lists) are used to isolate users from each other. Programs can share data by accessing the same file if they can both access it. There are special files called sockets that allow for network-like inter-process communication but of course two programs on the same computer can also connect (virtually) via the computer network (no data will actually go through a cable).
Interlude: Resource Types¶
As another diversion, let us consider how Unix manages its resources. This is important to understand when requesting resources from the scheduler later on.
First of all, a computer might offer a certain feature such as a specific hardware platform or special network connection.
Examples for this on the BIH HPC are specific Intel processor generations such as haswell or the availability of Infiniband networking.
You can request these with so-called constraints; they are not allocated to specific jobs.
Second, there are resources that are allocated to specific jobs. The most important resources here are:
- computing resources (processors/CPUs (central progressing units) and cores, details are explained below),
- main memory / RAM,
- special hardware such as GPUs, and
- (wall-clock) time that a job wants to run as an upper bound.
Generally, once a resource has been allocated to one job, it is not available to another. This means if you allocating more resources to your job that you actually need (overallocation) then those resources are not available to other jobs (whether they are your jobs or those of other users). This will be explained further below.
Another example of resource allocation are licenses. The BIH HPC has a few Matlab 2016b licenses that users can request. As long as a license is allocated to one job, it is unavailable to another.
Nodes, Sockets, Processors, Cores, Threads¶
Regarding compute resources, Slurm differentiates between:
- nodes: a compute server,
- sockets: a socket in the compute server that hosts one physical processor,
- processor: a CPU or a CPU core in a multi-core computer (all CPUs in the BIH HPC are multi-core), and
- (hardware) threads: most Intel CPUs feature hardware threads (also known as "hyperthreading") where each core appears to be two cores.
In most cases, you will use one compute node only. When using more than one node, you will need to use some form of message passing, e.g., MPI, so processes on different nodes can communicate. On a single node you would mostly use single- or multi-threaded processes, or multiple processes.
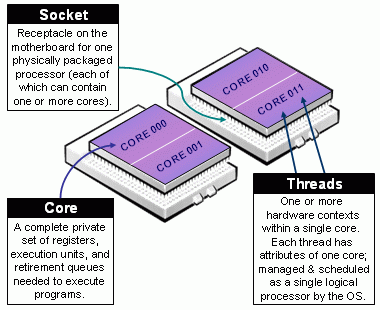
Above: Slurm's nomenclature for sockets, processors, cores, and threads (from Slurm Documentation).
Co-locating processes/threads on the same socket has certain implications that are mostly useful for numerical applications. We will not further go into detail here. Slurm provides many different features of ways to specify allocation of "pinning" to specific process locations. If you need this feature, we trust that you find sufficient explanation in the Slurm documentation.
Usually, you would allocate multiple cores (a term Slurm uses synonymously with processors) on a single node (allocation on a single node is the default).
How Scheduling Works¶
Slurm is an acronym for "Simple Linux Unix Resource Manager" (note that the word "scheduler" does not occur here). Actually, one classically differentiates between the managing of resources and the scheduling of jobs that use them. The resource manager allocates resources according to a user's request for a job and ensures that there are no conflicts. If the required resources are not available, the scheduler puts the user's job into a queue. Later, when then requested resources become available the scheduler assigns them to the job and runs it. In the following, both resource allocation and the running of the job are described as being done by the scheduler.
The interesting case occurs when there are not enough resources available for at least two jobs submitted to the scheduler. The scheduler has to decide how to proceed. Consider the simplified case of only scheduling cores. Each job will request a number of cores. The scheduler will then generate a scheduling plan that might look as follows.
core
^
4 | |---job2---|
3 | |---job2---|
2 | |---job2---|
1 | |--job1--|
+--------------------------> t time
5 1 1 2
0 5 0
job1 has been allocated one core and job2 has been allocated two cores.
When job3, requesting one core is submitted at t = 5, it has to wait at least as long until job1 is finished.
If job3 requested two or more cores, it would have to wait at least until job2 also finished.
We can now ask several questions, including the following:
- What if a job runs for less than the allocated time? -- In this case, resources become free and the scheduler will attempt to select the next job(s) to run.
- What if a job runs longer than the allocated time? -- In this case, the scheduler will send an informative Unix signal to the process first. The job will be given a bit more time and if it does not exit it will be forcibly terminated. You will find a note about this at the end of your job log file.
- What if multiple jobs compete for resources? -- The scheduler will prefer certain jobs over others using the Slurm Multifactor Priority Plugin. In practice, small jobs will be preferred over large, users with few used resources in the last month will be favored over heavy consumers, long-waiting jobs will be favored over recently submitted jobs, and many other factors. You can use the sprio utility to inspect these factors in real-time.
- How does the scheduler handle new requests? -- Generally, the scheduler will add new jobs to the waiting queue. The scheduler regularly adjusts its planning by recalculating job priorities. Slurm is configured to perform computationally simple schedule recalculations quite often and larger recalculations more infrequently.
Also see the Slurm Frequently Asked Questions.
Please note that even if all jobs were known at the start of time, scheduling is still a so-called NP-complete problem. Entire computer science journals and books are dedicated only to scheduling.
Things get more complex in the case of online scheduling, in which new jobs can appear at any time.
In practice, Slurm does a fantastic job with its heuristics but it heavily relies on parameter tuning.
HPC administration is constantly working on optimizing the scheduler settings.
Note that you can use the --format option to the squeue command to request that it shows you information
about job scheduling (in particular, see the %S field, which will show you the expected start time for a job,
assuming Slurm has calculated it). See man squeue for details.
If you observe inexplicable behavior, please notify us at hpc-helpdesk@bih-charite.de.
Slurm Partitions¶
In Slurm, the nodes of a cluster are split into partitions. Nodes are assigned to one or more partition (see the Job Scheduler section for details). Jobs can also be assigned to one or more partitions and are executed on nodes of the given partition.
In the BIH HPC, partitions are used to stratify jobs of certain running times and to provide different quality of service (e.g., maximal number of CPU cores available to a user for jobs of a certain running time and size).
The partitions gpu and highmem provide special hardware (the nodes are not assigned to other partitions) and the mpi partition allows MPI-parallelism and the allocation of jobs to more than one node.
The Job Scheduler provides further details.