Nodes and Storage Volumes¶
No mounting on the cluster itself.
For various technical and security-related reasons, it is not possible to mount anything on the cluster nodes by users. That is, it is not possible to get file server mounts on the cluster nodes. For mounting the cluster storage on your computer, see Connecting: SSHFS Mounts.
This document gives an overview of the nodes and volumes on the cluster.
Cluster Layout¶
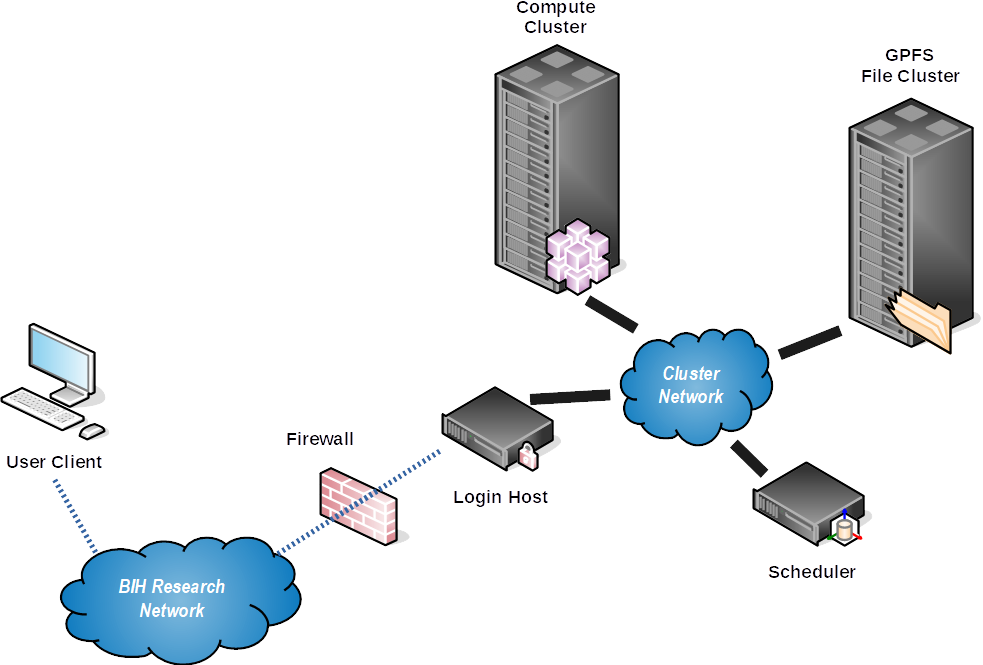
Cluster Nodes¶
The following groups of nodes are available to cluster users. There are a number of nodes that are invisible to non-admin staff, hosting the queue master and monitoring tools and providing backup storage for key critical data, but these are not shown here.
hpc-login-{1,2}- available as
hpc-login-{1,2}.cubi.bihealth.org - do not perform any computation on these nodes!
- these nodes are not execution nodes
- each process may at most use 1GB of RAM to increase stability of the node
- available as
med0101..0124,0127- 25 standard nodes
- Intel Xeon E5-2650 v2 @2.60Ghz, 16 cores x2 threading
- 128 GB RAM
med0133..0164- 32 standard nodes
- Intel Xeon E5-2667 v4 @3.20GHz, 16 cores x 2 threading
- 192 GB RAM
med0201..0264- 64 nodes with Infiniband interconnect
- Intel Xeon E5-2650 v2 @2.60Ghz, 16 cores x2 threading
- 128 GB RAM
med0301..0304- 4 nodes with 4 Tesla V100 GPUs each
med0401..0405special purpose/high-memory machines- Intel Xeon E5-4650 v2 @2.40GHz, 40 cores x2 threading
med0401andmed0402- 1 TB RAM
med0403andmed0404- 500 GB RAM
med0405- 2x "Tesla K20Xm" GPU accelleration cards (cluster resource
gpu) - access limited to explicit GPU users
- 2x "Tesla K20Xm" GPU accelleration cards (cluster resource
med0601..0616- 16 nodes owned by CUBI
- Intel Xeon E5-2640 v3 @2.60Ghz
- 192 GB RAM
med0618..0633- 16 nodes owned by CUBI
- Intel Xeon E5-2667 v4 @3.20GHz, 16 cores x 2 threading
- 192 GB RAM
med0701..0764- 64 standard nodes
- Intel Xeon E5-2667 v4 @3.20GHz, 16 cores x 2 threading
- 192 GB RAM
If not noted anyway, currently no access restrictions apply per se.
Cluster Volumes and Locations¶
The cluster has 2.1 PB of fast storage, currently available at /fast.
The storage runs on a DDN appliance using the IBM GPFS file system and is designed for massively parallel access from an HPC system.
In contrast to "single server" NFS systems, the system can provide large bandwidth to all cluster nodes in parallel as long as large data means relatively "few" files are read and written.
The GPFS storage is split into three sections:
home-- small, persistent, and safe storage, e.g., for documents and configuration files (default quota of 1GB).work-- larger and persistent storage, e.g., for your large data files (default quota of 1TB).scratch-- large and non-persistent storage, e.g., for temporary files, files are automatically deleted after 2 weeks (default quota of 100TB; deletion not implemented yet).)
Each user, group, and project has one of the sections each, e.g., for users:
/fast/users/$NAME/fast/users/$NAME/work/fast/users/$USER/scratch
See Storage and Volumes: Locations for more informatin.